
Configuring Data Relationships
|
|
Configuring Data Relationships |
Referential Integrity
Introduction
At this time, we know that there is useful functionality in creating relationships between tables as they allow the user to select existing information instead of typing it. This flow of information brings up issues about what happens if data that exists in a parent table gets deleted while such information has been made available to another table.
When manipulating data that is in a relationship, it is very important to make sure that data keeps its accuracy from one table or source to the other. To accomplish that goal, some rules must be established to "watch" or monitor the flow of information between two tables. Data or referential integrity is used to check that two tables are related through one (sometimes more than one) field on each table used as the primary key and the foreign key, data entered in the foreign key of a child table must exist in the parent table, otherwise it would be rejected. Only two fields of the same data type are used to establish a relationship between two tables, the tables involved in the relationship belong to the same database.
Cascades on Related Records
After creating a legitimate relationship between two tables, you must make sure that when data changes in the parent table, this change is reflected in the child table. For example, if a bank customer changes her last name after getting married or after a divorce, you should be able to change her name in one object (table) and the related objects, such as the one used to process her transactions would receive the changes without your having to make the change on each object (table). In the same way, when data is deleted, the objects that are related to it must also have that data deleted.
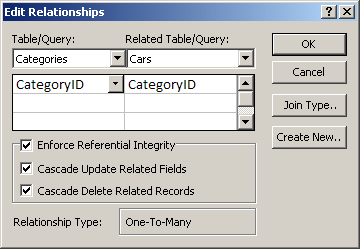
To enforce the rules of data integrity, Microsoft Access provides three check boxes in the Edit Relationship dialog box. First, if you want Microsoft Access to monitor data flow, you can click the Enforce Referential Integrity check box. This would make available two check boxes.
The Direction of a Relationship
The One-To-Many Relationship
As mentioned already, a relationship between two tables allows one table, the parent, to make its information available to another table (the child). Because in this case the user is asked to select information, it is likely that the same record on a parent table can be tied to various records in the child table. For example, one customer at a bank can deposit an amount of money today. The same customer can make another deposit tomorrow and even another deposit next month. In such a case, the relationship between the tables would show various entries of the same customer's account number in the object (table) used to deposit money but with different transactions. This type of relationship is known as one-to-many because one entry in the parent table can result in many entries in the child table.
To create a one-to-many relationship, check all three referential integrity check boxes and click Create. The parent table would have a 1 sign on its side of the joining line. The child table would have the infinity symbol on its side of the joining line.
![]() Practical
Learning: Managing Referential Integrity
Practical
Learning: Managing Referential Integrity


|
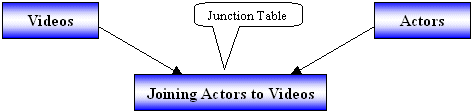
The Many-to-Many Relationship |
Although one-to-many is the most common type of relationship applied to records of a table, in some databases, you may need to create a relationship in which many records from one table A can have many related records in another table B and vice versa. This type of relationship is known as many-to-many. For example, in our Video Collection database:
To implement this type of relationship, you can create what is called a junction table. A junction table is a table whose main purpose is to bring together fields from other tables, creating a type of cross relationship for the necessary fields:
A junction table contains at least three fields. The
first field, almost less engaged, is used as the primary key, the same
type of field almost every table has. The other fields hold data that
would originate from other tables.
You can create a junction table
either in Datasheet View or in Design View:
You can also switch to either view to create a junction table. In other words, you can create one field in one view and create the other field in the other view.
![]() Practical Learning: Creating Junction Tables
Practical Learning: Creating Junction Tables
| Field Name | Data Type | Caption | Field Size |
| VideoActorID (Primary Key) |
AutoNumber | Video Actor ID | |
| VideoID | Number | Video | Long Integer |
| ActorID | Number | Actor | Long Integer |
| VideoActorID | VideoID | ActorID |
| 1 | 1 | 1 |
| 2 | 3 | 4 |
| 3 | 2 | 23 |
| 4 | 4 | 6 |
| 5 | 1 | 7 |
| 6 | 9 | 5 |
| 7 | 6 | 2 |
| 8 | 4 | 14 |
| 9 | 1 | 9 |
| 10 | 2 | 8 |
| 11 | 3 | 19 |
| 12 | 1 | 10 |
| 13 | 6 | 17 |
| 14 | 3 | 20 |
| 15 | 1 | 11 |
| 16 | 4 | 16 |
| 17 | 3 | 18 |
| 18 | 1 | 15 |
| 19 | 12 | 21 |
| 20 | 6 | 3 |
| 21 | 2 | 5 |
| 22 | 1 | 13 |
| 23 | 5 | 1 |
| 24 | 12 | 22 |
| 25 | 1 | 12 |
|
The One-to-One Relationship |
A one-to-one relationship is the type of junction between two tables A and B so that one record in table A can have only one corresponding entry in table B and vice versa. Because this is similar to one table of records, this type of relationship is hardly used since you can as well simply create one table.
Data Joins
|
Introduction |
When creating relationships among tables, we were selecting the primary key of one table. Here is an example of such a table:

We also know how to create a foreign key of a dependent table to join them. Here is an example named GenderID:

Once such a relationship is created, you can create a query that combines both tables to create a set of records, also called a record set, that would include either all records or isolate only the records that have entries. For example, imagine you have created a Persons table as follows where the Gender of a record is selected from a lookup field:

Suppose you want to create a query that includes the persons of this table and their genders. A question that comes is mind is: Do you want to create a list of only people who can be recognized by their gender, or do you want the list to include everybody? This concept leads to what are referred to as joins of queries. There are two ways you can get such queries: you can prepare the relationship between two tables to be aware of this type of relationship or you can directly create it when designing a query.
|
Inner Joins |
When building a query, you select fields and ask Microsoft Access to isolate them as being part of the query. Most of the time, you will want only fields that include a type of validation of your choice (a criterion). An inner join is the kind of query that presents only fields that have matching entries in both tables of a relationship. For example, from the above Persons table, you may want to create a query that includes only persons whose records contain the gender:

You would create the query as an inner join:

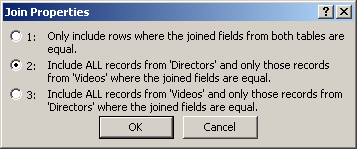
To specify that a relationship is inner join on tables, after creating the relationship, while in the Relationships, you can display its Edit Relationship dialog box and click Join Type. The Join Properties dialog box presents three options that allow you to define the direction of the relationship between the tables.
To specify an inner join in a SQL statement, you include INNER JOIN in the statement. For example, the code of the above query is:
SELECT Persons.FirstName,
Persons.LastName,
Genders.Gender
FROM Genders INNER JOIN Persons ON Genders.GenderID = Persons.GenderID;
![]() Practical
Learning: Creating Inner Join Relationships
Practical
Learning: Creating Inner Join Relationships




|
Outer Joins |
The queries we have used so far and that were based on related tables allowed us to get only the fields that had entries based on the established relationships. Fields that did not follow the rules were excluded. Instead of excluding fields, the SQL allows you to create a query that includes all fields, not just those that follow rules, as long as the records are part of either table. Such a query is referred to as outer join. To manage the result of this type of query, the SQL considers the direction of a relationship.
When creating relationships, we learned to drag a primary key from one table, the parent, to a dependent table, the child. In this type of relationship, the table (or query) that holds the origin of the relationship is referred to as the Left table. The other table is referred to as the right table. Based on this, there are two types of outer joins: the left join represented in SQL as LEFT JOIN and the right join represented by RIGHT JOIN.
As done with the inner join relationship, the left and right joins can be prepared in the Relationships window on tables. If the query has already been created and you want to change its direction, you can change it in the Design View of the query where you would first right-click the joining line and click:

In the Join Properties dialog box, click the radio button that has 2:
And click OK.
After creating a relationship or while working on
relationships, you can create a visual report of the result and be able to
print it when necessary. To create the report, in the Tools section of the
Ribbon, click the Relationship Report button
![]() ,
which would highlight it
,
which would highlight it
![]() .
This action would automatically generate a report with the relationships
designed on it. To keep the report, you should save it and give it a name.
You can then print it as you would print any other report.
.
This action would automatically generate a report with the relationships
designed on it. To keep the report, you should save it and give it a name.
You can then print it as you would print any other report.
![]() Practical
Learning: Creating a Relationship Report
Practical
Learning: Creating a Relationship Report
|
Fundamentals of Indexes |
|
Introduction |
An index is a list of words that makes it easy to locate a section in a document. For a table of a database, an index is one column or a list of columns that can make it easily to locate one or more records.
If you create a table that has a primary key, the database engine automatically creates an index. If you want, you can accept that index, delete that default index, or create a new one. Before creating an index, you must have document on which the index will be based. Before creating an index for a database, you must first create a table. With the table ready, before creating the index, you must identify the column(s) you want to use.
![]() Practical
Learning: Introducing Indexes
Practical
Learning: Introducing Indexes
| Field Name | Data Type | Field Size | Caption | Format |
| StoreItemCode | Text | 10 | Store Item Code | |
| CarYear | Number | Integer | Car Year | |
| Make | Text | 40 | ||
| Model | Text | 40 | ||
| Category | Text | 32 | ||
| ItemName | Text | 50 | Item Name | |
| UnitPrice | Number | Double | Unit Price | Fixed |
|
Creating an Index |
Once you have the table, you can create an index. To visually create an index, open the table in Design View. Then, in the Show/Hide section of the Ribbon, click Indexes. This would display the Indexes window. To create an index, under the Index Name column, type a name. Then, click the arrow of the corresponding Field Name combo box and select the column used as the index. Once you are ready, close the Indexes window.
![]() Practical
Learning: Creating an Index
Practical
Learning: Creating an Index
|
Deleting an Index |
To remove an existing index, display the table in Design View. In the Show/Hide section, click Indexes. In the Indexes window, right-click the index and click Delete Rows.
Characteristics of an Index
|
A Primary Key as an Index |
If a table has a primary key, that primary key’s column(s) is used as the index. If the primary key doesn’t exist, to transform your index into a primary key, under the Index Name column, select the index. Then, in the lower part of the window, change the value of Primary from No (the default for a non-primary key) to Yes.
|
Sorting the Records in an Index |
The best way for an index to keep track of its records is to sort them:
If the column is text-based, the records would be sorted in alphabetical order. This is referred to as ascending. You can also sort the records in reverse alphabetical order. This is referred to as descending.
If you are visually creating an index, to specify the sorting order, click the combo box in the third column under Sort Order and select either Ascending or Descending.
![]() Practical
Learning: Sorting the Records of an Index
Practical
Learning: Sorting the Records of an Index

|
Restricting Unique Values |
Like a primary key, an index can be used to control how records are created on its table. For example, an index can check that each new record has a unique value in the indexed column. To do this visually, in the top section of the Indexes window, select the index name. In the bottom section, set the Unique column to Yes. When this is set, no new record can use a value that was already set on a previous record.
If the records were already created and when data analysis is made, if two records have the same value, only the first record would be considered.
![]() Practical
Learning: Restricting Unique Values on an Index
Practical
Learning: Restricting Unique Values on an Index
|
Allowing or Disallowing Null Values |
In the absence of a primary key, an index is a valuable helper to controlling data entry. In the absence of a primary key, you can ask an index to make sure that the value of its column is not left empty when a new record is created. To set this rule, in the top section of the Indexes window, select the index. In the bottom section, set the Ignore Null column to No, which is the default already. When this is set, the user cannot move to the next record if no value was given to the indexed column.
If the records were already created, during data analysis, the records with a null value would be ignored.
![]() Practical
Learning: Disallowing Null Values on an Index
Practical
Learning: Disallowing Null Values on an Index
Lesson Summary
|
MCAS: Using Microsoft Office Access 2007 Topics |
| S2 | Define and print table relationships |
|
Exercises |
Yugo National Bank

Watts A loan
| Field Name | Data Type | Additional Information |
| LoanEvaluationID | AutoNumber | Primary Key Caption: Loan Evaluation ID |
| LoanAmount | Currency | Caption: Loan Amount Default Value: 0 |
| InterestRate | Number | Field Size: Double Format: Percent Caption: Interest Rate Default Value: 0.0875 |
| NumberOfPeriods | Number | Field Size: Integer Caption: NumberOfPeriods Default Value: 12 |
Save the table as LoanEvaluation and close it
|
|
||
| Previous | Copyright © 2010-2019, FunctionX | Next |
|
|
||