Aggregate Queries

Aggregate Queries
Introduction to Aggregate Functions
Overview
Microsoft SQL Server can be used to serve different goals. For example, a statistician can use it to keep records and analyze the meaning of numbers stored in tables and views. To assist with this, Transact-SQL provides many statistic-based functions, referred to as aggregate functions. They make it possible to create particular views named aggregate queries.
Transact-SQL provides many built-in functions used to get statistics. These functions are used in various circumstances, depending on the nature of the column being investigated. This means that you should first decide what type of value you wand to get, then choose the appropriate function. To call the function in SQL code, start a SELECT statement and pass the column to the function. The minimum formula to follow is:
SELECT FunctionName(FieldName) FROM TableName;
To visually create an aggregate query, in the Object Explorer, expand the database you want to use. Right-click Views and click New View... On the Add Table dialog box, select the table(s) (or view(s)) and close it. To start a summary query:
This would add a new column titled Group By in the Criteria section. From that column, you can select the function you want to use. Later, we will review what aggregate functions are available.
![]() Practical Learning: Introducing Aggregate Functions
Practical Learning: Introducing Aggregate Functions
The Number of Rows (The Size of a Sample)
Probably the most basic piece of information you may want to get about a list is the number of records it has. In statistics, this is referred to as the number of samples. To help you get this information, Transact-SQL provides a function named Count. It counts the number of records in a column and produces the total. This function also counts NULL fields. The syntax of the Count() function is:
int COUNT ( { [ [ ALL | DISTINCT ] expression ] | * } )
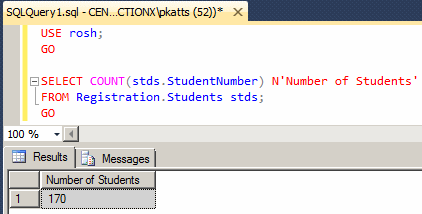
This function takes one argument. The Count() function returns an int value. Here is an example:
USE rosh;
GO
SELECT COUNT(stds.StudentNumber) N'Number of Students'
FROM Registration.Students stds;
GO
This would produce:
To get the count of occurrences of a value, in the Criteria pane, you can select COUNT(*).
If you are working on a large number of records, you can call the Count_Big() function. Its syntax is:
bigint COUNT_BIG ( { [ ALL | DISTINCT ] expression } | * )
![]() Practical Learning: Getting the Number of Records
Practical Learning: Getting the Number of Records
USE MonsonUniversity1; GO SELECT COUNT(Studs.StudentNumber) [Number of Students] FROM Studs; GO
USE MonsonUniversity1; GO SELECT COUNT_BIG(Regs .RegistrationID) [Total Registrations] FROM Regs; GO
The Minimum Value of a Series
If you have a list of values, you may want to get the
lowest value. For example, in a list of houses of a real estate company
with each property having a price, you may want to know which house is the
cheapest. To let you get this information, Transact-SQL provides a
function named MIN. Its syntax is:
DependsOnType MIN ( [ ALL | DISTINCT ] expression )
The return value of the MIN() function depends on the type of value that is passed to it. For example, if you pass a column that is number-based, the function returns the highest number. Here is an example:
USE DepartmentStore1;
GO
SELECT MIN(si.UnitPrice) N'Cheapest'
FROM Inventory.StoreItems si;
GO
If you pass a string-based column, the function returns the the last value in the alphabetical order. Here is an example:
USE rosh;
GO
SELECT MIN(stds.LastName) [First Student]
FROM Registration.Students stds;
GO
In the same way, you can pass a date/time-based column. Here is an example:
USE rosh;
GO
SELECT MIN(stds.DateOfBirth) "Youngest Student"
FROM Registration.Students stds;
GO
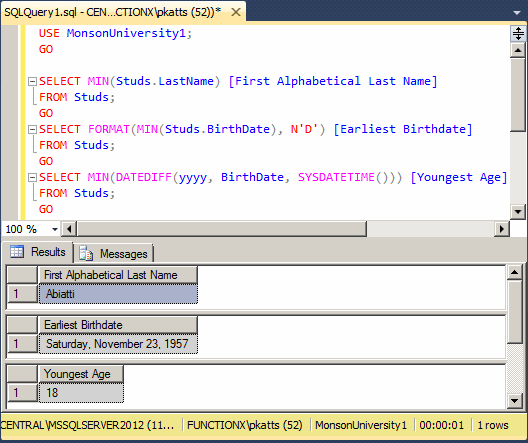
Be careful when passing a value to an aggregate function such as MIN(). For example, if the name of a column is processed by a function, the returned value would be used by the aggregate function. Consider the following call:
SELECT MIN(FORMAT(Studs.BirthDate, N'D')) [Earliest Birthdate] FROM Studs; GO
This would produce:

Notice that the name Friday, as a string, is the one being processed by the MIN() function, instead of the actual date.
![]() Practical
Learning: Getting the Minimum of a Series
Practical
Learning: Getting the Minimum of a Series

USE MonsonUniversity1; GO SELECT MIN(Studs.LastName) [First Alphabetical Last Name] FROM Studs; GO SELECT FORMAT(MIN(Studs.BirthDate), N'D') [Earliest Birthdate] FROM Studs; GO SELECT MIN(DATEDIFF(yyyy, BirthDate, SYSDATETIME())) [Youngest Age] FROM Studs; GO
The Maximum Value of a Series
The opposite of the lowest is the highest value of a
series. To assist you with getting this value, Transact-SQL provides the
Max() function. Its function is:
DependsOnType MAX ( [ ALL | DISTINCT ] expression )
This function follows the same rules as its MIN() counterpart, but in reverse order (of the rules). Here is an example:
USE DepartmentStore1;
GO
SELECT MAX(si.UnitPrice) N'Most Expensive'
FROM Inventory.StoreItems si;
GO
![]() Practical
Learning: Getting the Highest Value of a Series
Practical
Learning: Getting the Highest Value of a Series

|
The Sum of Values |
The sum of the values of a series is gotten by adding all values. In algebra and statistics, it is represented as follows:
∑x
To let you calculate the sum of values of a certain
column of a table, Transact-SQL provides a function named Sum. The
syntax of the Sum() function is:
Number SUM ( [ ALL | DISTINCT ] expression )
Unlike the MIN() and the MAX() functions that can receive a column of almost any type, the column passed to the SUM() function must be number-based.
![]() Practical Learning: Getting the Sum of Value
Practical Learning: Getting the Sum of Value

The Mean
In algebra and statistics, the mean is the average of the numeric values of a series. To calculate it, you can divide the sum by the number of values of the series. It is calculated using the following formula:
![]()
From this formula:
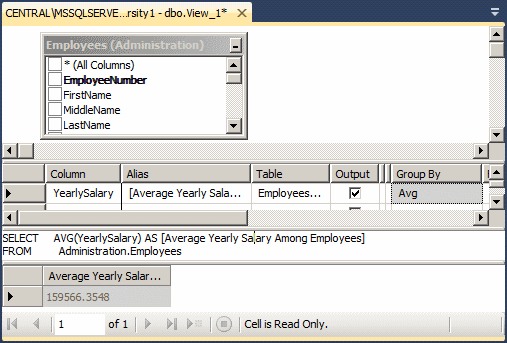
To support this operation, Transact-SQL provides the
Avg function. Its syntax is:
Number AVG ( [ ALL | DISTINCT ] expression )
USE MonsonUniversity1; GO SELECT AVG(DATEDIFF(yyyy, Studs.BirthDate, SYSDATETIME())) [Average Student Age] FROM Studs; GO
|
The Standard Deviation of a Series |
Imagine you have a column with numeric values. You already know how to get the sum and the mean. The standard deviation is a value by which the elements vary (deviate) from the mean. The formula to calculate the standard deviation is:

From this formula:
The above formula wants you to first calculate the mean. As an alternative, you can use a formula that does not require the mean. It is:
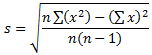
Instead of creating your own function, Transact-SQL
can assist you. First there are two types of standard deviations. The
sample standard deviation relates to a sample. To let you calculate it,
Transact-SQL provides a function named STDDEV. Its syntax is:
float STDEV ( [ ALL | DISTINCT ] expression )
The other standard deviation relates to a population. To help you calculate it, Transact-SQL provides the STDDEVP() function. Its syntax is:
float STDEVP ( [ ALL | DISTINCT ] expression )
![]() Practical Learning: Getting the Standard Deviation
Practical Learning: Getting the Standard Deviation

USE MonsonUniversity1; GO SELECT STDEVP(DATEDIFF(yyyy, Studs.BirthDate, SYSDATETIME())) [Students Ages Deviation] FROM Studs; GO
The Variance of a Series
The variance is the square of the standard deviation. This means that, to calculate it, you can just square the value of a standard deviation. As seen with the standard deviation, there are two types of variances. A sample variance relates to a sample. To help you calculate a sample variance of records, Transact-SQL provides VAR function. Its syntax is:
float VAR ( [ ALL | DISTINCT ] expression )
The function used to calculate a population variance is VARP and its syntax is:
float VARP ( [ ALL | DISTINCT ] expression )
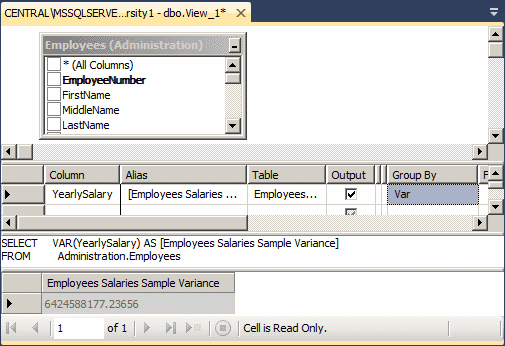
![]() Practical
Learning: Getting the Sample Variance
Practical
Learning: Getting the Sample Variance
Intermediate Aggregate Operations
Grouping the Values of an Aggregate Query
As we have seen so far, the simplest way to use an aggregate function is to consider one column and pass it to the function. As we know already, most tables use more than one column. This gives you the option to create groups of records and present the rows in groups. Both SQL and Transact-SQL provide many options.
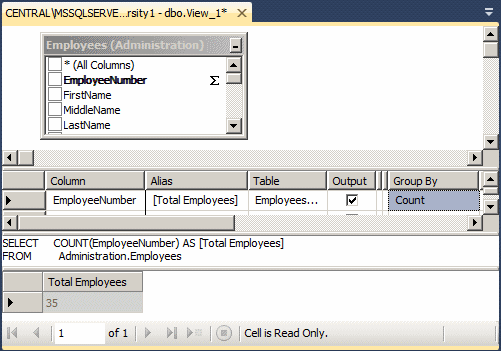
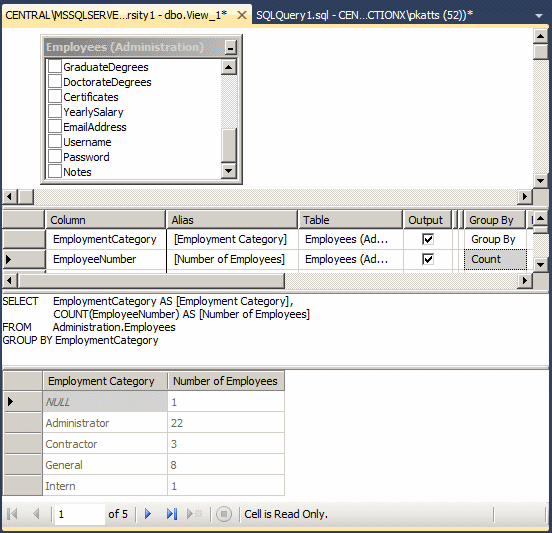
We have already seen how to visually create an aggregate query by starting a view and clicking the Add Group By button. As you may have suspected, the Add Group By option actually allows you to visually create groups of records in the Criteria section. In reality, to visually create a group of records, you should select more than one column in the Criteria pane. You must then select Group By for one of thes column and select the desired aggregate function for the other column.
To create a group of records using an aggregate function, the formula to follow is:
SELECT WhatField(s) FROM WhatObject(s) GROUP BY Column(s)
The new expression in this formula is GROUP BY. This indicates that you want to group some values from one or more columns. There are rules you must follow.
Although you can create an aggregate query with all fields or any field(s) of a view, the purpose of the query is to summarize data. For a good summary view, you should use a column where the records hold categories of data. This means that the records in the resulting view have to be grouped by categories. The GROUP BY expression means that, where the records display, they would be grouped by their categories.
As stated already, the purpose of an aggregate query is to provide some statistics. Therefore, it is normal that you be interested only in the column(s) that hold(s) the desired statistics and avoid the columns that are irrelevant. As a result, if you select (only) the one column that holds the information you want, in the resulting list, each of its categories would display only once.
![]() Practical
Learning: Grouping the Values of an Aggregate Query
Practical
Learning: Grouping the Values of an Aggregate Query
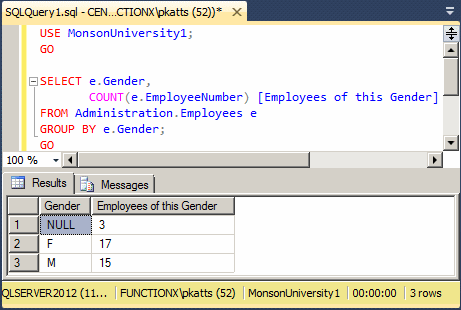
USE MonsonUniversity1;
GO
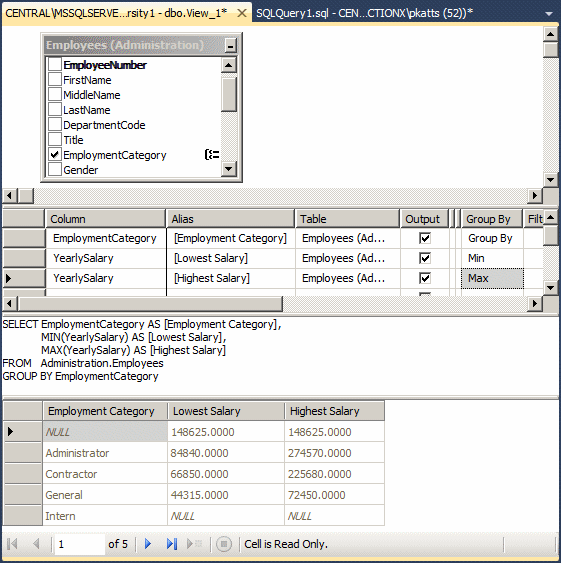
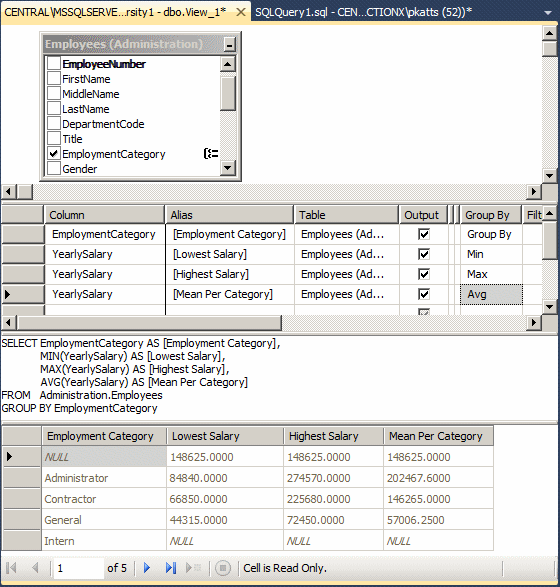
SELECT e.Gender,
COUNT(e.EmployeeNumber) [Employees of this Gender]
FROM Administration.Employees e
GROUP BY e.Gender;
GO
USE MonsonUniversity1;
GO
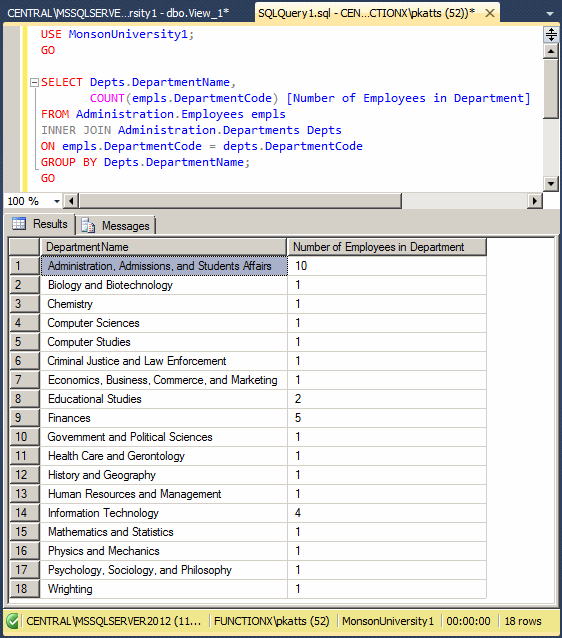
SELECT Depts.DepartmentName,
COUNT(empls.DepartmentCode) [Number of Employees in Department]
FROM Administration.Employees empls
INNER JOIN Administration.Departments Depts
ON empls.DepartmentCode = depts.DepartmentCode
GROUP BY Depts.DepartmentName;
GO
Applying a Condition to an Aggregate Query
Consider the following summary view that calls the Count(*) function:
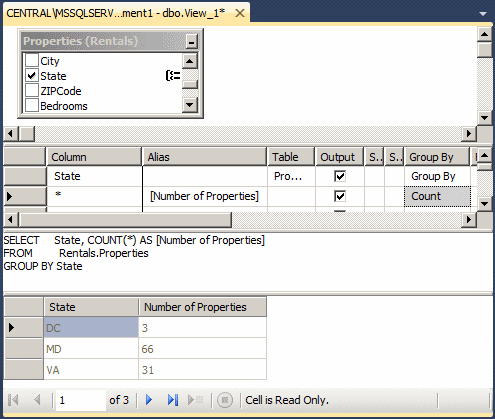
Imagine you want to include only records that have a certain value in an aggregate query. To assist you with setting a condition, you can use a Where option. To visually do this, in the Criteria pane, add the column on which the summary should be applied and select Where for the Group By field. Then, in the equivalent Filter box, type the condition, and execute the statement.
To programmatically set a condition in an aggregate query, use the following formula:
SELECT WhatField(s) FROM WhatObject(s) WHERE Condition GROUP BY Column(s)
Notice that the WHERE clause is stated before the GROUP BY section. Here is an example:
USE LambdaPropertiesManagement1;
GO
SELECT COUNT(props.PropertyNumber) [Number of Apartments]
FROM Rentals.Properties props
WHERE props.PropertyType = N'Apartment';
GO
In the same way, you can apply a condition to any of the other aggregate functions we saw already. If you include more than one column in your statement, then you must add a GROUP BY clause. Here is an example:
USE LambdaPropertiesManagement1; GO SELECT props.PropertyType, COUNT(*) [Number of Properties] FROM Rentals.Properties props WHERE props.PropertyType IS NOT NULL GROUP BY props.PropertyType; GO
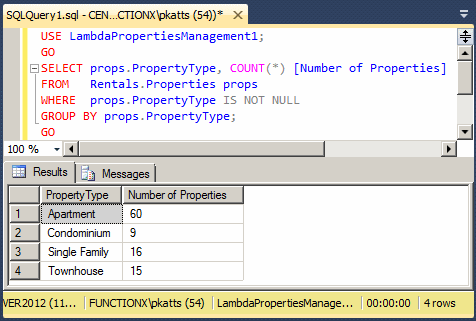
![]() Practical
Learning: Applying a Condition to an Aggregate Query
Practical
Learning: Applying a Condition to an Aggregate Query
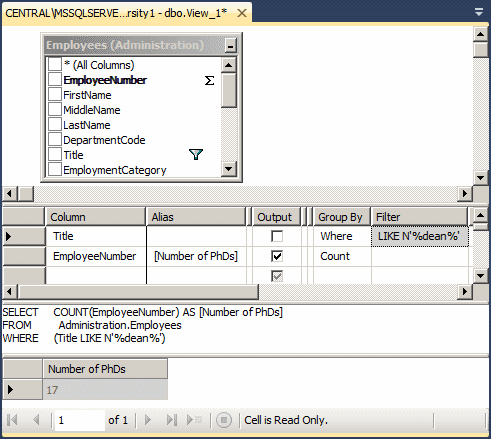
USE MonsonUniversity1; GO SELECT stds.MajorID, COUNT(stds.StudentNumber) Effective FROM Studs stds GROUP BY stds.MajorID; GO

USE MonsonUniversity1; GO SELECT majs.Major, COUNT(stds.StudentNumber) Effective FROM Studs stds INNER JOIN Academics.UndergraduateMajors majs ON stds.MajorID = majs.MajorID GROUP BY majs.Major; GO
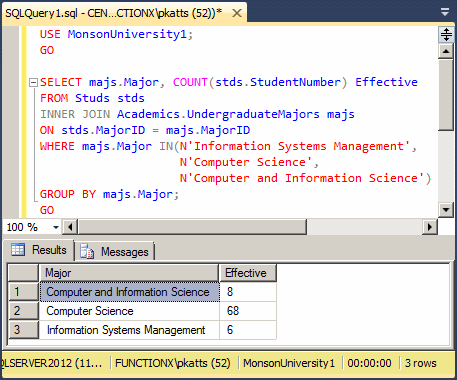
USE MonsonUniversity1; GO SELECT majs.Major, COUNT(stds.StudentNumber) Effective FROM Studs stds INNER JOIN Academics.UndergraduateMajors majs ON stds.MajorID = majs.MajorID WHERE majs.Major IN(N'Information Systems Management', N'Computer Science', N'Computer and Information Science') GROUP BY majs.Major; GO
When we mentioned a Where condition in our summary views, we saw that we had to add a duplicate column to apply it. As an alternative, to support conditions in an aggregate query, you can add a clause named HAVING to the statement. The formula to follow is:
SELECT What FROM WhatObject(s) GROUP BY Column(s) HAVING Condition
The new operator in this formula is HAVING. It allows you to specify the criterion by which the SELECT statement should produce its results.
|
|
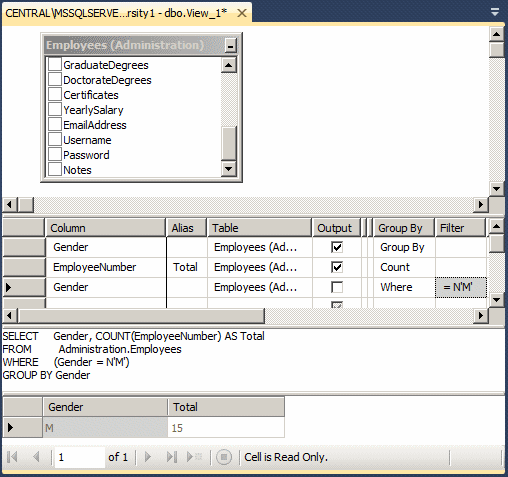
USE MonsonUniversity1;
GO
SELECT Gender,
COUNT(EmployeeNumber) AS Total
FROM Administration.Employees
GROUP BY Gender
HAVING Gender = N'M';
GO
USE MonsonUniversity1;
GO
SELECT majs.Major, COUNT(stds.StudentNumber) Effective
FROM Studs stds
INNER JOIN Academics.UndergraduateMajors majs
ON stds.MajorID = majs.MajorID
GROUP BY majs.Major
HAVING majs.Major IN(N'Information Systems Management',
N'Computer Science',
N'Computer and Information Science');
GO
Using an Expression
As its name indicates, the Expression option allows you to write your own expression that will be applied on the column.
![]() Practical
Learning: Using an Expression in an Aggregate Query
Practical
Learning: Using an Expression in an Aggregate Query
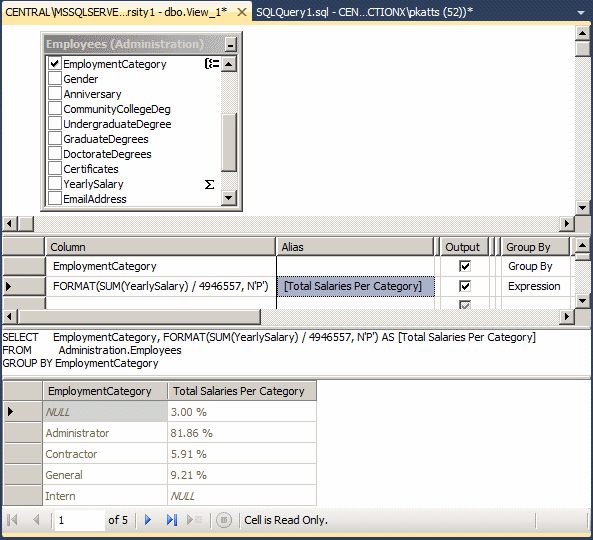
USE MonsonUniversity1;
GO
SELECT Gender,
FORMAT(SUM(YearlySalary) / 4946557, N'P') AS [Total Salaries Per Gender]
FROM Administration.Employees
GROUP BY Gender;
GO
|
|
The above code was using a constant number that represents the total of employees salaries. If a new employee gets hired or an employee leaves the company, the result of that statement would become invalid. Here is a better version of the statement, using a sub-query: SELECT EmploymentCategory,
FORMAT(SUM(YearlySalary) / (SELECT SUM(YearlySalary)
FROM Administration.Employees),
N'P')
AS [Total Salaries Per Category]
FROM Administration.Employees
GROUP BY EmploymentCategory
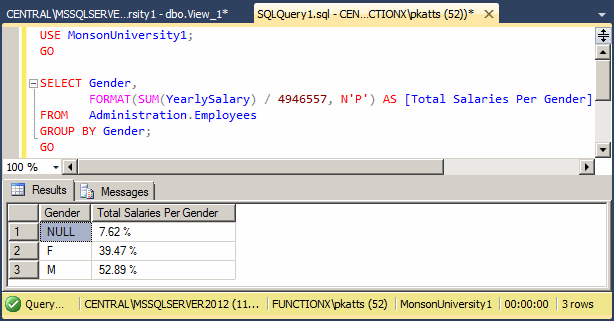
And here is a better version for the other statement: SELECT Gender,
FORMAT(SUM(YearlySalary) / (SELECT SUM(YearlySalary)
FROM Administration.Employees),
N'P')
AS [Total Salaries Per Gender]
FROM Administration.Employees
GROUP BY Gender;
GO
|
Computing an Aggregate Function
Imagine you have a table that has one or more fields with numeric values and you use a SELECT statement to select some of those columns. At the end the statement, you can ask the database engine to perform a calculation using one or more of the aggregate functions and show the result(s). To do this, you use the COMPUTE keyword in a formula as follows:
[ COMPUTE
{ { AVG | COUNT | MAX | MIN | STDEV | STDEVP | VAR | VARP | SUM }
( expression ) } [ ,...n ]
[ BY expression [ ,...n ] ]
]
As you see, you start with COMPUTE followed by the desired function, which uses parentheses. In the parentheses, include the name of the column that holds the numeric values.
![]() Practical
Learning: Ending the Lesson
Practical
Learning: Ending the Lesson
|
|
||
| Previous | Copyright © 2008-2022, FunctionX, Inc. | Next |
|
|
||