|
Assistance with Data Entry: The Nullity of a Field |
|
During data entry, users of your database will face
fields that expect data. Sometimes, for one reason or another, data will
not be available for a particular field. An example would be an MI (middle
initial) field: some people have a middle initial, some others either
don't have it or would not (or cannot) provide it. This aspect can occur
for any field of your table. Therefore, you should think of a way to deal
with it.
A field is referred to as null when no data entry has
been made to it:
- Saying that a field is null doesn't mean that it contains 0 because
0 is a value
- Saying that a field is null doesn't mean that it is empty. A field
being empty could mean that the user had deleted its content or that
the field itself would not accept what the user was trying to enter
into that field, but an empty field can have a value
A field is referred to as null if there is no way of
determining the value of its content (in reality, the computer, that is,
the operating system, has its own internal mechanism of verifying the
value of a field) or its value is simply unknown. As you can imagine, it is
not a good idea to have a null field in your table. As a database
developer, it is your responsibility to always know with certainty the
value held by each field of your table.
A field is referred to as required if the user must
provide a value for it before moving to another record. In other words,
the field cannot be left empty during data entry.
To solve the problem of null and required fields,
Microsoft SQL Server
proposes one of two options: allow or not allow null values on a field.
For a typical table, there are pieces of information that the user should
make sure to enter; otherwise, the data entry would not be
validated. To make sure the user always fills out a certain field before
moving to the next field, that is, to require the value, if you are
visually creating the table, clear the
Allow Nulls check box for the field. On the other hand, if the value of a
field is not particularly important, for example if you don't intend to
involve that value in an algebraic operation, check its Allow Nulls check box.
If creating a table using SQL, to specify that it can
allow null values, type NULL on the right side of the column. To
specify that the values of the column are required, on the right side,
type NOT NULL. If you don't specify NULL or NOT NULL, the column
will be created as NULL. Here are examples:
CREATE TABLE Persons
(
FirstName varchar(20) NULL,
LastName varchar(20) NOT NULL,
Gender smallint
);
GO
If the table was already created and it holds some
values already, you cannot set the Allow Nulls option on columns that
don't have values.
After specify that a column would NOT allow NULL values, if
the user tries creating a record but omits to create a value for the column, an
error would display. Here is an example:
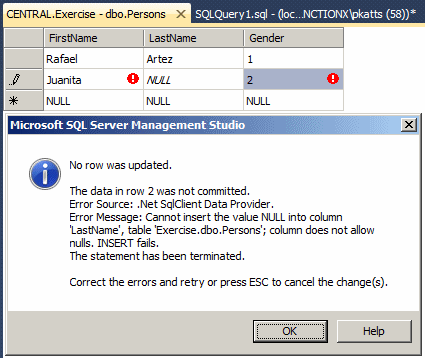
This error message box indicates that the user attempted to
submit a null value for a column. To cancel the action, you can press Esc.
|
 Practical
Learning: Applying Fields Nullity Practical
Learning: Applying Fields Nullity
|
|
- In the Object Explorer, right-click Countries in the WorldStatistics
node and click Modify
- Apply the nullity of fields as follows:
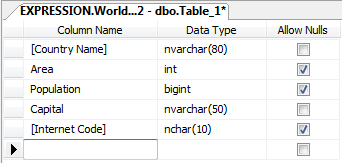
- Save the table
|
Assistance with Data Entry: The Default Value of a Column |
|
Sometimes most records under a certain column may hold the
same value although just a few would be different. For example, if a school is
using a database to register its students, all of them are more likely to be
from the same state. In such a case, you can assist the user by automatically providing
a value for that column. The user would then simply accept the value and change
it only in the rare cases where the value happen to be different. To assist the
user with this common value, you create what is referred to as a default value.
|
Visually Creating a Default Value |
|
You can create a default value of a column when creating a
table. To specify the default value of a column, in the top section, click the
column. In the bottom section, click Default Value or Binding, type the desired
value following the rules of the column's data type:
| It the Data Type is |
Intructions |
| Text-based (char,
varchar, text,
and their variants) |
Enter the value in single-quotes |
| Numeric-based |
Enter the value as a number but
following the rules of the data type.
For example, if you enter a value higher than 255 for a tinyint,
you would receive an error |
| Date or Time |
Enter the date as either MM/DD/YYYY or
YYYY/MM/DD. You can optionally include the date in
single-quotes.
Enter the time following the rules set in the Control Panel (Regional
Settings). |
| Bit |
Enter True or False |
|
Programmatically Creating a Default Value |
|
To specify the default value in a SQL statement, when
creating the column, after specifying the other pieces of information of the
column, type DEFAULT followed by an empty space and followed by the
desired value. Here are
examples:
CREATE TABLE Employees
(
FullName VARCHAR(50),
Address VARCHAR(80),
City VARCHAR(40),
State VARCHAR(40) DEFAULT 'NSW',
PostalCode VARCHAR(4) DEFAULT '2000',
Country VARCHAR(20) DEFAULT 'Australia'
);
GO
After creating the table, the user does not have to provide a
value for a column that has a default. If the user does not provide the value,
the default would be used when the record is saved.
 |
If the user provides a value for a column that has a
default value and then deletes the value, the default value rule would not
apply anymore: The field would simply become empty |
|
Practical
Learning: Assigning a Default Value to a Column
|
|
- Display the PowerShell window
- To change the database, type the
following and press Enter at the end:
- To create a new table whose columns have default values, type the
following and press Enter at the end:
CREATE TABLE Rooms (
RoomNumber nvarchar(10),
RoomType nvarchar(20) default N'Bedroom',
BedType nvarchar(40) default N'Queen',
Rate money default 75.85,
Available bit default 0
);
GO
|
- To perform data entry on the new table, type the following and press
Enter at the end:
INSERT INTO Rooms(RoomNumber) VALUES(104);
GO
|
- To add another record to the new table, type the following:
INSERT INTO Rooms(RoomNumber, BedType, Rate, Available)
VALUES(105, N'King', 85.75, 1),
(106, N'King', 85.75, 1)
GO
|
- To add another record, type the following:
INSERT INTO Rooms(RoomNumber, Available) VALUES(107, 1)
GO
|
- To add another record, type the following:
INSERT INTO Rooms(RoomNumber, BedType, Rate) VALUES(108, N'King', 85.75)
GO
|
- To add another record, type the following:
INSERT INTO Rooms(RoomNumber, Available) VALUES(109, 1)
GO
|
- To add one more record, type the following:
INSERT INTO Rooms(RoomNumber, RoomType, BedType, Rate, Available)
VALUES(110, N'Conference', N'', 450.00, 1)
GO
|
- Return to Microsoft SQL Server Management Studio
|
Assistance with Data Entry: Identity Columns |
|
One of the goals of a good table is to be able to
uniquely identity each record. In most cases, the database engine should
not confuse two records. Consider the following table:
| Category |
Item Name |
Size |
Unit Price |
| Women |
Long-sleeve jersey dress |
Large |
39.95 |
| Boys |
Iron-Free Pleated Khaki Pants |
S |
39.95 |
| Men |
Striped long-sleeve shirt |
Large |
59.60 |
| Women |
Long-sleeve jersey dress |
Large |
45.95 |
| Girls |
Shoulder handbag |
|
45.00 |
| Women |
Continental skirt |
Petite |
39.95 |
Imagine that you want to change the value of an item
named Long-sleeve jersey dress. Because you must find the item
programmatically, you can start looking for an item with that name. This
table happens to have two items with that name. You may then decide to
look for an item using its category. In the Category column, there are too
many items named Women. In the same way, there are too many records that
have a Large value in the Size column, same thing problem in the Unit
Price column. This means that you don't have a good criterion you can use
to isolate the record whose Item Name is Long-sleeve shirt.
To solve the problem of uniquely identifying a record,
you can create a particular column whose main purpose is to distinguish
one record from another. To assist you with this, the SQL allows you to
create a column whose data type is an integer type but the user doesn't
have to enter data for
that column. A value would automatically be entered into the field when a
new record is created. This type of column is called an identity column.
You cannot create an identity column one an existing
table, only on a new table.
|
Visually Creating an Identity Column |
|
To create an identity column, if you are visually
working in the design view of the table, in the top section, specify the
name of the column. By tradition, the name of this column resembles that
of the table but in singular. Also, by habit, the name of the column ends
with _id, Id, or ID.
After specifying the name of the column, set its data
type to an integer-based type. Usually, the data type used is int. In the bottom section, click
and expand the Identity Specification property. The first action
you should take is to set its (Is Identity) property from No to Yes.
Once you have set
the value of the (Is Identity) property to Yes, the first time the
user performs data entry, the value of the first record would be set to 1.
This characteristic is controlled by the Identity Seed property. If
you want the count to start to a value other than 1, specify it on this
property.
After the (Is Identity) property has been set to Yes, the
SQL interpreter would increment the value of each new record by 1, which
is the default. This means that the first record would have a value of 1, the second would have a value of
2, and so on. This aspect is controlled by the Identity Increment
property. If you want to increment by more than that, you can change
the value of the Identity Increment property.
|
Practical
Learning: Creating an Identity Column
|
|
- In the Object Explorer, under WorldStatistics, right-click Tables
and click New Table...
- Set the name of the column to ContinentID and press Tab
- Set its data type to int and press F6.
In the lower section of the table, expand Identity Specification and
double-click (Is Identity) to set its value to Yes
- Complete the table as follows:
| Column Name |
Data Type |
Allow Nulls |
| ContinentID |
|
|
| Continent |
varchar(80) |
Unchecked |
| Area |
bigint |
|
| Population |
bigint |
|
- Save the table as Continents
|
Creating an Identity Column Using SQL |
|
If you are programmatically creating a column, to
indicate that it would be used as an identity column after its name and
data type, type identity followed by parentheses. Between the
parentheses, enter the seed value, followed by a comma, followed by the increment
value. Here is an example:
CREATE TABLE StoreItems(
ItemID int IDENTITY(1, 1) NOT NULL,
Category varchar(50),
[Item Name] varchar(100) NOT NULL,
Size varchar(20),
[Unit Price] money);
GO
|
Practical
Learning: Creating an Identity Column Using SQL
|
|
- Display the PowerShell window
- Type the following:
- To create a table with an identity column, type the following and
press Enter after each line:
DROP TABLE Rooms;
GO
CREATE TABLE Rooms (
RoomID int identity(1, 1) NOT NULL,
RoomNumber nvarchar(10),
RoomType nvarchar(20) default N'Bedroom',
BedType nvarchar(40) default N'Queen',
Rate money default 75.85,
Available bit default 0
);
GO
|
- To perform data entry on the new table, type the following and press
Enter at the end:
INSERT INTO Rooms(RoomNumber) VALUES(104);
GO
|
- To add another record to the new table, type the following:
INSERT INTO Rooms(RoomNumber, BedType, Rate, Available)
VALUES(105, N'King', 85.75, 1),
(106, N'King', 85.75, 1)
GO
|
- To add another record, type the following:
INSERT INTO Rooms(RoomNumber, Available) VALUES(107, 1)
GO
|
- To add another record, type the following:
INSERT INTO Rooms(RoomNumber, BedType, Rate) VALUES(108, N'King', 85.75)
GO
|
- To add another record, type the following:
INSERT INTO Rooms(RoomNumber, Available) VALUES(109, 1)
GO
|
- To add one more record, type the following:
INSERT INTO Rooms(RoomNumber, RoomType, BedType, Rate, Available)
VALUES(110, N'Conference', N'', 450.00, 1)
GO
|
- Return to Microsoft SQL Server Management Studio
|
Assistance with Data Entry: The Uniqueness of
Records |
|
One of the primary concerns of records is their uniqueness.
In a professional database, you usually want to make sure that each record on a
table is unique. Microsoft SQL Server provides many means of taking care of
this. These include the identity column, the primary key, and the indexes. We
will review these issues in later lessons. Still, one way to do this is to apply
a uniqueness rule on a column.
|
Creating a Uniqueness Rule |
|
To assist you with creating a columns whose values will be
distinguishable, Transact-SQL provides the UNIQUE operator. To apply it
on a column, after the data type, type UNIQUE. Here is an example:
USE Exercise;
GO
CREATE TABLE Students
(
StudentNumber int UNIQUE,
FirstName nvarchar(50),
LastName nvarchar(50) NOT NULL
);
GO
When a column has been marked as unique, during data entry,
the user must provide a unique value for each new record created. If an existing
value is assigned to the column, this would produce an error:
USE Exercise;
GO
CREATE TABLE Students
(
StudentNumber int UNIQUE,
FirstName nvarchar(50),
LastName nvarchar(50) NOT NULL
);
GO
INSERT INTO Students
VALUES(24880, N'John', N'Scheels'),
(92846, N'R�n�e', N'Almonds'),
(47196, N'Peter', N'Sansen'),
(92846, N'Daly', N'Camara'),
(36904, N'Peter', N'Sansen');
GO
By the time the fourth record is entered, since it uses a
student number that exists already, the database engine would produce an error:
Msg 2627, Level 14, State 1, Line 2
Violation of UNIQUE KEY constraint 'UQ__Students__DD81BF6C145C0A3F'.
Cannot insert duplicate key in object 'dbo.Students'.
The statement has been terminated.
|
Practical
Learning: Applying Uniqueness to a Column
|
|
- In the PowerShell window, to create a new table that has a
uniqueness rule on a column, type the following:
CREATE TABLE Customers (
CustomerID int identity(1, 1) NOT NULL,
AccountNumber nchar(10) UNIQUE,
FullName nvarchar(50)
);
GO
|
- To perform data entry on the table, type the following and press
Enter at the end of each line:
INSERT INTO Customers(AccountNumber, FullName)
VALUES(395805, N'Ann Zeke'),
(628475, N'Peter Dokta'),
(860042, N'Joan Summs')
GO
|
- To try adding another record to the table, type the following and press
Enter at the end of each line:
USE CeilInn1;
GO
INSERT INTO Customers(AccountNumber, FullName)
VALUES(628475, N'James Roberts')
GO
|
- Notice that you receive an error
|
Assistance With Data Entry: Check Constraints |
|
When performing data entry, in some columns, even
after indicating the types of values you expect the user to provide for a
certain column, you may want to restrict a range of values that are allowed. In
the same way, you can create a rule that must be respected on a combination of
columns before the record can be created. For example, you can ask the database
engine to check that at least one of two columns received a value. For example,
on a table that holds information about customers, you can ask the database
engine to check that, for each record, either the phone number or the email
address of the customer is entered.
The ability to verify that one or more rules are respected
on a table is called a check constraint. A check constraint is a Boolean operation performed
by the SQL interpreter. The interpreter examines a value that has just been
provided for a column. If the value is appropriate:
- The constraint produces TRUE
- The value gets accepted
- The value is assigned to the column
If the value is not appropriate:
- The constraint produces FALSE
- The value gets rejected
- The value is not assigned to the column
You create a check constraint at the time you are creating a
table.
|
Visually Creating a Check Constraint |
|
To create a check constraint, when creating a table,
right-click anywhere in (even outside) the table and click Check
Constraints...
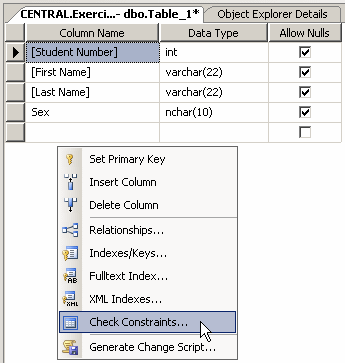
This would open the Check Constraints dialog box. From that
window, you can click Add. Because a constraint is an object, you must provide a name for it. The most important
piece of information that a check constraint should hold is the mechanism it
would use to check its values. This is provided as an expression. Therefore, to
create a constraint, you can click Expression and click its ellipsis button.
This would open the Check Constraint Expression dialog box.
To create the expression, first type the name of the column
on which the constraint will apply, followed by parentheses. In the parentheses,
use the arithmetic and/or SQL operators we studied already. Here is an example
that will check that a new value specified for the Student Number is greater
than 1000:
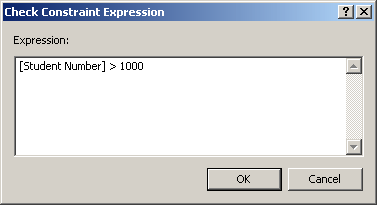
After creating the expression, you can click OK. If the
expression is invalid, you would receive an error and given the opportunity to
correct it.
You can create as many check constraints as you judge
necessary for your table:
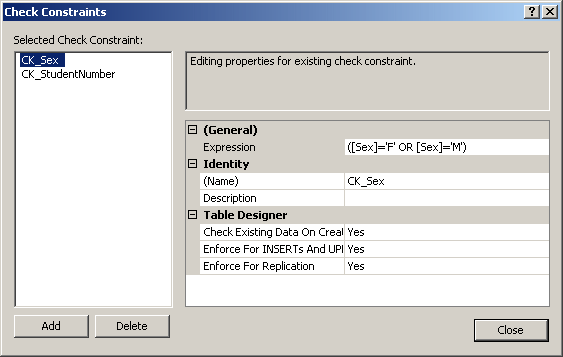
After creating the check constraints, you can click OK.
|
Programmatically Creating a Check Constraint |
|
To create a check constraint in SQL, first create the
column on which the constraint will apply. Before the closing parenthesis of the table definition, use the
following formula:
CONSTRAINT name CHECK (expression)
The CONSTRAINT and the CHECK keywords are
required. As an object, make sure you provide a name for it. Inside the
parentheses that follow the CHECK operator, enter the expression that will be
applied. Here is an example that will make sure that the hourly salary specified
for an employee is greater than 12.50:
CREATE TABLE Employees
(
[Employee Number] nchar(7),
[Full Name] varchar(80),
[Hourly Salary] smallmoney,
CONSTRAINT CK_HourlySalary CHECK ([Hourly Salary] > 12.50)
);
It is important to understand that a check constraint it
neither an expression nor a function. A check constraint contains an expression
and may contain a function as part of its definition.
After creating the constraint(s) for a table, in the Object
Explorer of Microsoft SQL Server Management Studio, inside the table's node,
there is a node named Constraints and, if you expand it, you would see the name
of the constraint.
With the constraint(s) in place, during data entry, if the
user (or your code) provides an invalid value, an error would display. Here is
an example:
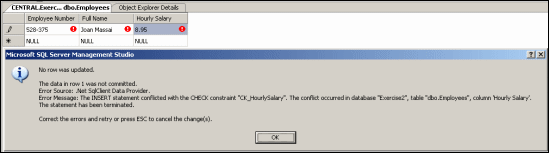
Instead of an expression that uses only the regular
operators, you can use a function to assist in the checking process. You can
create and use your own function or you can use one of the built-in Transact-SQL
functions.
|
Practical
Learning: Creating a Check Constraint
|
|
- In the PowerShell window, to create a table that has a check
mechanism, type the following:
DROP TABLE Customers;
GO
CREATE TABLE Customers (
CustomerID int identity(1, 1) NOT NULL,
AccountNumber nchar(10) UNIQUE,
FullName nvarchar(50) NOT NULL,
PhoneNumber nvarchar(20),
EmailAddress nvarchar(50),
CONSTRAINT CK_CustomerContact
CHECK ((PhoneNumber IS NOT NULL) OR (EmailAddress IS NOT NULL))
);
GO
|
- To add records to the new table, type the following:
INSERT INTO Customers(AccountNumber, FullName,
PhoneNumber, EmailAddress)
VALUES(N'395805', N'Ann Zeke', N'301-128-3506', N'azeke@yahoo.jp'),
(N'628475', N'Peter Dokta', N'(202) 050-1629',
N'pdorka1900@hotmail.com'),
(N'860042', N'Joan Summs', N'410-114-6820', N'jsummons@emailcity.net');
GO
|
- To try adding a new record to the table, type the following:
INSERT INTO Customers(AccountNumber, FullName)
VALUES(N'228648', N'James Roberts')
GO
|
- Notice that you receive an error.
Close the PowerShell window
|
Assistance With Data Entry: Using Functions |
|
You can involve a function during data entry. As an
example, you can call a function that returns a value to assign that value
to a column. You can first create your own function and use it, or you can
use one of the built-in functions.
In order to involve a function with your data entry,
you must have and identity one. You can use one of the built-in functions
of Transact-SQL. You can check one of the functions we reviewed in Lesson
8. Normally, the best way is to check the online documentation to find
out if the assignment you want to perform is already created. Using a
built-in function would space you the trouble of getting a function. For
example, imagine you have a database named AutoRepairShop and imagine it
has a table used to create repair orders for customers:
CREATE TABLE RepairOrders
(
RepairID int Identity(1,1) NOT NULL,
CustomerName varchar(50),
CustomerPhone varchar(20),
RepairDate datetime2
);
GO
When performing data entry for this table, you can let
the user enter the customer name and phone number. On the other hand, you
can assist the user by programmatically entering the current date. To do
this, you would call the GETDATE()
function. Here are examples:
INSERT INTO RepairOrders(CustomerName, CustomerPhone, RepairDate)
VALUES(N'Annette Berceau', N'301-988-4615', GETDATE());
GO
INSERT INTO RepairOrders(CustomerPhone, CustomerName, RepairDate)
VALUES(N'(240) 601-3795', N'Paulino Santiago', GETDATE());
GO
INSERT INTO RepairOrders(CustomerName, RepairDate, CustomerPhone)
VALUES(N'Alicia Katts', GETDATE(), N'(301) 527-3095');
GO
INSERT INTO RepairOrders(RepairDate, CustomerPhone, CustomerName)
VALUES(GETDATE(), N'703-927-4002', N'Bertrand Nguyen');
GO
You can also involve the function in an operation,
then use the result as the value to assign to a field. You can also call a
function that takes one or more arguments; make sure you respect the rules
of passing an argument to a function when calling it.
If none of the Transact-SQL built-in functions satisfies your requirements, you can create your own, using the techniques
we studied in Lesson 7.
|
Other Features of Data Entry |
|
This property allows you to specify
that a column with the Identity property set to Yes is used as a
ROWGUID
column.
Because different languages use
different mechanisms in their alphabetic characters, this can affect the
way some sort algorithms or queries are performed on data, you can ask the
database to apply a certain language mechanism to the field by changing the
Collation property. Otherwise, you should accept the default specified by
the table.
To find out what language your server is currently
using, in a Query window or from PowerShell, you can type:
SELECT @@LANGUAGE;
GO
- Record
- Row
- Table Navigation
- Visual Data Entry
- SQL Data Entry
- Adjacent Data Entry
- Random Data Entry
- Default Values
- Identity Columns
- Expressions
- Check Constraints
- Collation
- Data Import
- Selecting Records
- Editing Records
- Updating Records
- Deleting Records
|
Keywords, Operators, and Properties
|
|
- NULL
- NOT NULL
- DEFAULT
- IDENTITY
- Identity Specification
- (Is Identity)
- Identity Seed property
- Identity Increment
- CONSTRAINT
- CHECK
- Collation
- databases
- EXISTS
- UPDATE
- DELETE
|
|