Transact-SQL Data Entry
|
Transact-SQL Data Entry |
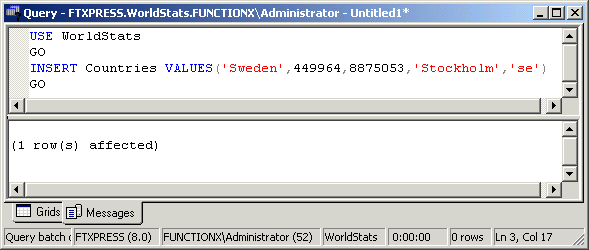
In the SQL, data entry is performed using the INSERT combined with the VALUES keywords. The primary statement uses the following syntax: INSERT TableName VALUES(Column1, Column2, Column_n) Alternatively, or to be more precise, you can specify that you are entering data in the table using the INTO keyword between the INSERT keyword and the TableName factor. This is done with the following syntax: INSERT INTO TableName VALUES(Column1, Column2, Column_n) The TableName factor must be a valid name of an existing table in the database you are using. If the name is wrong, the SQL would simply consider that the table you are referring to doesn't exist. Consequently, you would receive an error. The VALUES keyword indicates that you are ready to list the values of the columns. The values of the columns must be included in parentheses. If the column is a BIT data type, you must specify one of its values as 0 or 1. If the column is a numeric type, you should pay attention to the number you type. If the column was configured to receive an integer (int, bigint, smallint), you should provide a valid natural number without the decimal separator. If the column is for a decimal number (float, real, decimal, numeric), you can type the value with its character separator (the period for US English). If the column was created for a date data type, make sure you provide a valid date. If the data type of a column is a string type, you should include its entry between single quotes. For example, a shelf number can be specified as 'HHR-604' and a middle initial can be given as 'D'.
The most common technique of performing data entry requires that you know the sequence of fields of the table in which you want to enter data. With this subsequent list in mind, enter the value of each field in its correct position. During data entry on adjacent fields, if you don't have a value for a numeric field, you should type 0 as its value. For a string field whose data you don't have and cannot provide, type two single-quotes '' to specify an empty field.
|
|
Random Data Entry |
|
The adjacent data entry we have been performing requires that you know the position of each field. The SQL provides an alternative that allows you to perform data entry using the name of a column instead of its position. This allows you to provide the values of columns in an order of your choice. We have just seen a few examples where the values of some of the fields are not available during data entry. Instead of remembering to type 0 or NULL for such fields or leaving empty quotes for a field, you can use their names to specify the fields whose data you want to provide. To perform data entry at random, you must provide a list of the fields of the table in the order of your choice. You can either use all columns or provide a list of the same columns but in your own order. In the same way, you don't have to provide data for all fields, just those you want, in the order you want. |
|
|
|
|
Data Entry and the Identity Column |
|
Introduction |
|
One of the goals of a good table is to be able to uniquely identity each record. In most cases, the database engine should not confuse two records. Consider the following table:
Imagine that you want to find the record of Sweden or that of Honduras. This table appears to have two entries for Sweden and both display the exact same information. So, which record is valid and which one would be used? To eliminate or reduce this confusion, you should create one particular column whose values would be used to (uniquely) represent each record. In some cases, you can allow the user to create the values of that column. For example, you can create a column in which the user would enter the employee number of each employee, making sure that each employee has a unique number throughout the company. Suppose that, during data entry, the user is not able to create, generate or provide a number for an employee (may be it is difficult; for example, if the company already has 4122 employees and the user needs to create a unique number for the new employee, the clerk would need to check every number to make sure that the new one is still available. This can be difficult). Instead of letting the user cre ate values of a column that uniquely identify each column, you can ask the interpreter to take care of this. In other words, the interpreter would create a new value for each new record. This type of column is called an identity column. |
|
|
|
|
Visually Creation of an Identity Column |
|
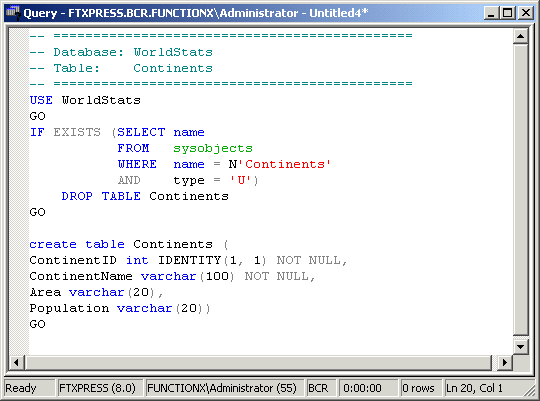
Using the SQL Server Enterprise Manager, you can add an identity column when creating a brand new table or you can add it to an existing table. If the table exists already, you can right-click it in the right frame and click Design Table. To create an identity column, first give it a name. By habits, the name of an identity column usually holds the singular name of the table and is appended with ID. For example, the identity column of an Employees table would be named EmployeeID. This is not a rule and is not enforced by the interpreter: it is only a suggestion. After setting the name of the column, you can specify its data type. If you want the user to provide the unique values of the fields under that column, you can use any string-based or number-based data type of your choice. If you want the database interpreter to be responsible for generating the unique values of that column, you should set its data type to int. After specifying the data type of the column, to actually indicate that the column will be managed as an identity column, you should set its Identity property to Yes. The default value is No, which would mean that the column is not used as an identifier. If the column is used as an identifier except when a replication is adding data to the table, you can set this property to Yes (Not For Replication). Identity Seed: If you set the Identity property to Yes, you can specify how the value would change for the field. For example, if you set the Identity to Yes and the column's data type is an integer, you can use the Identity Seed property to specify what would be the first number counted. This allows you to ask the database to start counting the numbers at a value other than 1 (the default). Identity Increment: If you specify the Identity property of a column as Yes, you can use the Identity Increment to specify how the counting would occur. By default, SQL Server would count numbers in increments of 1. An example would be 15, 16, 17, 18, etc. With a custom Identity Increment, you can use a number of 5 to increment as 15, 20, 25, 30, etc. |
|
|
|
|
SQL and the Identity Column |
|
If you are programmatically creating a column, to indicate that it would be used as an identity column after its name and data type, type identity followed by parentheses. Between the parentheses, enter the seed and the increment as we reviewed above. |
|
|
|
|
Other Features of Data Entry |
|
Is RowGuid |
This property allows you to specify that a column with the Identity property set to Yes is used as a ROWGUID column. |
|
Collation |
|
Because different languages use different mechanisms in their alphabetic characters, this can affect the way some sort algorithms or queries are performed on data, you can ask the database to apply a certain language mechanism to the field by changing the Collation property. Otherwise, you should accept the default specified by the table. |
|
|
||
| Previous | Copyright © 2005-2016, FunctionX | Next |
|
|
||